

The difference between a helpful AI agent and a useless one is good long-term memory management.
To keep it simple, let's think of long-term memory as stuff that goes into the prompt that wasn't produced by the user or the LLM within the current interaction. We can use long-term memory to provide the LLM agent with all kinds of information such as a summary of a lengthy conversation or the state of agent's current task. We could share knowledge about the user to adjust the agent's behavior, help it solve a problem by providing examples, or ground it in real-world documents. We might even tell it what other agents have to say on the matter.
In a perfect world you wouldn't need to bother with any of that, and would simply feed everything into the prompt and call it a day. But at least today, doing so efficiently and reliably is an open research problem.
Therein lies the complexity.
Normally you'd use a simple database table to store everything, and build your backend around it. Then you would turn your backend into a monstrosity that makes sure correct message histories, summaries, extracted values, and external resources get produced, persisted, indexed, and retrieved just in time to be plugged into the correct agent.
All while trying to keep user interactions responsive and fast.
In this article, we will explore how Gel's trigger system can simplify long-term memory management by offloading it to the background, where it belongs.
App overview
This part contains a bird's-eye look at the demo application. Feel free to skip to the next section if you would like to get straight to the point.
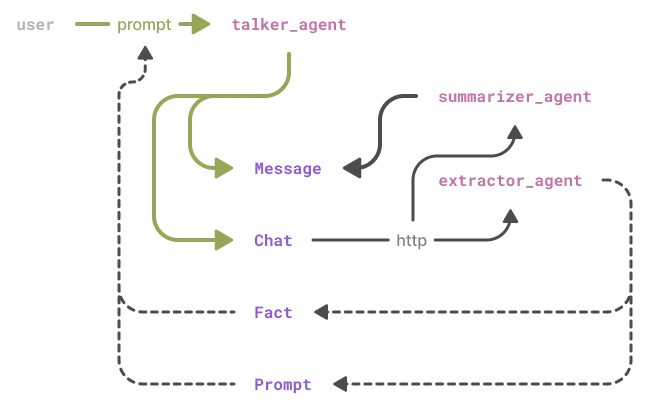
We'll be illustrating the concepts by examining at a high level this custom multi-agent chat bot. You can pull up this code to follow along and look more closely at the details, since we'll be staying at a high level for the rest of this post.
It's loosely designed after MemGPT and is meant to remember key information from interactions and adjust its persona based on user feedback. A system like this involves many LLM requests, which we'll distribute among three specialized agents:
-
Talker agent: The user-facing, user-aware agent with a defined persona. It's the one that generates answers to user messages.
-
Extractor agent: Works behind the scenes, extracting user information (facts) and feedback (behavior preferences) from chat history. These materials are used to tailor the chatbot to the user.
-
Summarizer agent: Another background agent that handles tasks like chat history compression and generating descriptive titles for conversations.
Naturally we will be using Gel for storage.
The web API is made using FastAPI. Its primary advantage for us is how out-of-the-way it can be when it comes to designing and gluing together the application. You'd have to look at the complete project to notice how sparse its presence is. Our focus here is on getting the agents to talk to each other, the user and the database, and we appreciate all the code we didn't have to write to make that happen.
Speaking of agents, they are built using Pydantic AI. It's one of the cleanest ways to build agents in Python, and it works really well with FastAPI thanks to their Pydantic-based interfaces and similar design.
The GUI is made with Streamlit. It has prebuilt chat parts, and that's about all we need for now.
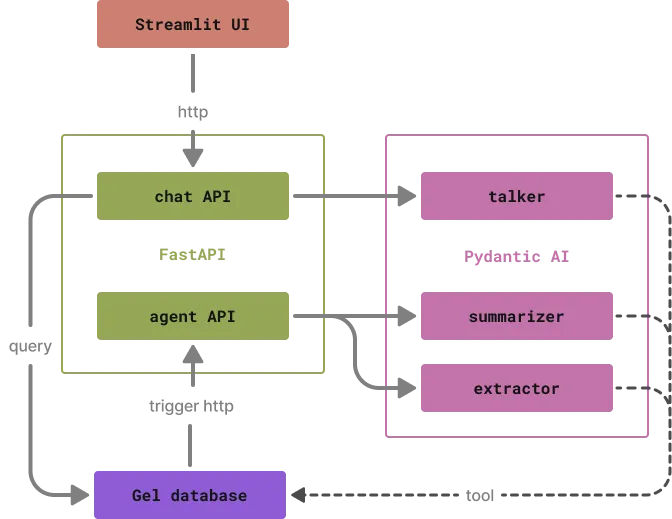
Let's look in more detail at how different parts interact with each other. First, check out this diagram and the project's file structure:
src/agent_mem
|
|-- agents # pydantic ai agent implementations
| |-- extractor.py
| |-- summarizer.py
| |-- talker.py
|-- routers
| |-- agent_api.py # fastapi endpoints for summary and extraction
| |-- chat_api.py # chat api endpoints (managing chats and messages, invoking the talker agent)
|-- db.py # gel client and queries
|-- gui.py # streamlit gui
|-- main.py # fastapi app-
The GUI is talking to the backend as usual, nothing to see here.
-
The backend forwards stuff from GUI to the LLM agent, also quite normal.
-
After the LLM responds, the backend stores everything in the database and returns the response to the GUI.
-
The database detects change in data and talks back to the backend to request background processing.
-
The backend once again forwards requests to the agents.
-
The agents have direct access to the database and store the processing results on their own volition.
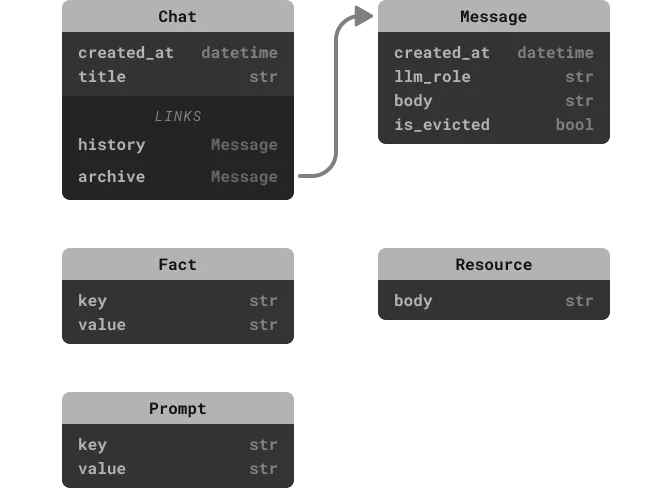
Let's also take a look at the types that make up the schema:
type Message {
llm_role: str;
body: str;
# message is timestamped when it's inserted into the database
created_at: datetime {
default := datetime_current();
};
# message is evicted if it's part of a summary and shouldn't
# be included in the chat history
is_evicted: bool {
default := false;
};
}
type Chat {
# chat is timestamped when it's inserted into the database
created_at: datetime {
default := datetime_current();
};
# chat title is "Untitled" by default, will be updated by
# the summarizer agent
title: str {
default := "Untitled";
};
# archive contains all of the messages, including the evicted ones
multi archive: Message;
# history is a computed value that excludes evicted messages
multi history := (
select .archive filter not .is_evicted
);
}
# this type is used by the agent to store and update facts about the user
type Fact {
key: str {
constraint exclusive;
}
value: str;
body := .key ++ ": " ++ .value;
}
# this type is used to keep track of the agent's persona
type Prompt {
key: str {
constraint exclusive;
}
value: str;
body := .key ++ ": " ++ .value;
}
# this type is used to store external information that the agent
# might access via a tool
type Resource {
body: str;
# this index automatically embeds the resource body and enables vector search
deferred index ext::ai::index(
embedding_model := "text-embedding-3-small"
) on (.body);
}The full code is available here.
So where's the long-term memory?
In the context of our application, the long-term memory consists of:
-
Two key-value stores (
FactandPrompttypes in our schema) that record facts about the user and agent behavior preferences. These are controlled by theExtractoragent. This data dynamically injects into theTalkeragent's system prompt, making it user-aware and personalizing its persona. -
A resource library (
Resourcetype) that acts as a normal RAG. TheTalkeragent has access to it as a tool. -
The chat history itself. Since it can be arbitrarily long, we're applying a recursive summary compression to make sure it doesn't overflow the prompt.
The key to responsive AI applications lies in keeping the primary interaction path lean.
Transformer models typically use cache to skip computation for tokens they've already seen, allowing them to rapidly predict one token after another. The only time a model has to do calculations for many tokens at once is when generating the first token – this is called "prefill". Prefill latency means there will always be a delay between the user sending a message and the agent responding, which leaves no room to run another beefy model in-between.
At the same time, running extraction and compression off the primary path could introduce its own realm of problems, like building a stateful backend, rolling your own event handling system and ensuring data consistency across services.
Luckily, Gel has a trigger system designed to automatically execute EdgeQL queries or schedule actions like HTTP requests when data changes. Since the database is meant to be the source of truth about the state of the application, this is the perfect place to orchestrate such background tasks.
Using the database to manage background tasks has a side effect when figuring out how to deploy the application. Specifically, it let's us simplify the backend back to simple HTTP endpoints. This let's us get away with the serverless deployment colocated with the frontend (e.g. Vercel Functions), which dramatically reduces the devops complexity.
Let's take a look at how we can take advantage of that.
Running extraction
In our application, we're injecting facts about the user and an agent persona into the Talker's system prompt.
Pydantic AI makes it tremendously easy to edit the system prompt on the fly in a clean type-safe way.
from pydantic_ai import Agent, RunContext
class TalkerContext(BaseModel):
# Model for agent's dependencies that have to be passed
# on every agent's invocation.
user_facts: list[str]
behavior_prompt: list[str]
agent = Agent("openai:gpt-4o-mini", deps_type=TalkerContext)
@agent.system_prompt
async def get_system_prompt(context: RunContext[TalkerContext]):
# Gets called on every agent's invocation
# to formulate the system prompt.
return PROMPT_TEMPLATE.format(
user_facts="\n".join(context.deps.user_facts),
behavior_prompt=context.deps.behavior_prompt,
)# agent's invocation (with streamed response)
async with talker_agent.run_stream(
user_message,
# special dependency model we defined above
deps=TalkerContext(
user_facts=user_facts,
behavior_prompt=behavior_prompt,
),
) as result:
async for text in result.stream_text():
yield textWe use a dedicated Extractor agent to manage both of these based on the user's feedback and conversation history.
# the context model only has a Gel client in it
agent = Agent("openai:gpt-4o-mini", deps_type=ExtractorContext)
@agent.system_prompt
async def get_system_prompt(context: RunContext[ExtractorContext]):
# show existing facts, give editing instructions
# key-value store tools that interact with the Gel database
@agent.tool
async def upsert_fact(context: RunContext[ExtractorContext], key: str, value: str):
# ...
@agent.tool
async def delete_fact(context: RunContext[ExtractorContext], key: str):
# ...Running the Extractor in the hot path (i.e., immediately after a user sends a message and before the Talker agent responds) would be redundant for the current turn, as the necessary information is already in the immediate chat context.
More importantly, it would add significant latency.
Instead, we can trigger the extractor after new messages are saved to the database.
-
When a
Chatobject is updated (e.g., by adding new messages to its archive), Gel fires a trigger. -
In this trigger, we schedule an HTTP POST request to a dedicated
/extractendpoint in our backend, passing thechat_id.
Here's how the trigger is defined in our Gel schema:
type Chat {
# ... other properties and links ...
# declaration of the trigger
trigger extract after update for each do (
# function that schedules the http request
select request_facts(__new__.id)
);
}For simplicity, we've hardcoded the host and port to our FastAPI backend here. Once you're ready to deploy, we can use Gel's globals mechanism to dynamically replace 127.0.0.1:8000 with the current deployment URL and to pass the authentication token securely.
For Vercel specifically, that would be the Protection Bypass for Automation.
Check out schema docs and Python client docs to learn what globals look like.
This request lands on our backend, which invokes the Extractor agent.
The Extractor then processes the entire chat history for that chat_id and uses its tools to add, update, or delete facts and behavior preferences in the database as it deems fit.
This is what it looks like on the other end of this interaction.
router = APIRouter()
class ExtractRequest(BaseModel):
chat_id: str
@router.post("/extract")
async def extract(
request: ExtractRequest,
gel_client=Depends(get_gel),
extractor_agent=Depends(get_extractor_agent),
):
chat_history = await gel_client.query_single(
"""
with chat := <Chat><uuid>$chat_id
select chat { history: { llm_role, body } };
""",
chat_id=request.chat_id,
)
formatted_messages = "\n\n".join([f"{m.llm_role}: {m.body}" for m in chat.history])
response = await extractor_agent.run(
f"""
Extract facts about the user or you go to jail.
{formatted_messages}
""",
# injection to let the agent reuse the Gel client
deps=ExtractorContext(
gel_client=gel_client,
),
)
return {"response": response.output}By handling extraction this way, we introduce no extra latency into the primary user-agent interaction path. This allows us to use a powerful model for extraction and still have the updated facts and preferences ready for the next interaction or chat session.
Now let's take a look at a task that requires a few more moving parts.
History compression
Recursive chat history summarization is another task that we can handle gracefully using triggers.
Essentially, when a chat history exceeds a certain length, we evict the oldest messages and replace them with a summary. This process is "recursive" because the summary itself is treated like any other message and can eventually be part of a subsequent, broader summary.
With a mechanism like this, we don't want to skimp on the summarization algorithm, otherwise the agent starts "forgetting" important details from earlier in the conversation (which never fails to tremendously annoy the user). Running a heavy summarization algorithm in the hot path would cause unacceptable latency, while running it completely detached would require an external task queue or a polling system.
Once again, Gel triggers provide an elegant solution. Every time a Chat is updated and its active history message count exceeds a defined global summary_threshold (and the last message was from the assistant, to avoid summarizing mid-turn), we trigger a summarization task.
The trigger looks like this:
# constants are stored as globals
# this one defines at what message count to request the summarization
global summary_threshold: int64 {
default := 5;
};
# this constant defines how many messages to leave unsummarized
global num_messages_to_leave: int64 {
default := 2;
};
type Chat {
# ... other properties and links ...
multi archive: Message;
multi history := (
select .archive filter not .is_evicted
);
trigger summarize after insert, update for each do (
with
# subquery for messages that will be left in the chat history
# the chat that set off the trigger is referred to as __new__
remaining_messages := (
select __new__.history
order by .created_at desc
limit global num_messages_to_leave
),
# get the newest of the remaining messages to determine the role
# (summary will be triggered after the assistant messages)
last_message := (
select remaining_messages
order by .created_at desc
limit 1
),
# get the oldest of the remaining messages to determine the cutoff timestamp
cutoff_message := (
select remaining_messages
order by .created_at asc
limit 1
),
# main query calls a function that's also defined in the schema
select request_summary(
__new__.id,
assert_exists(cutoff_message.created_at)
) if
# but only if the message count is over the threshold and it's the end of the turn
(count(__new__.history) > global summary_threshold)
and last_message.llm_role = "assistant"
else {}
);
}The request_summary function, also written in EdgeQL, then prepares the necessary data (chat ID, messages to summarize, cutoff timestamp) and schedules an HTTP POST request to our /summarize backend endpoint:
function request_summary(chat_id: uuid, cutoff: datetime) -> net::http::ScheduledRequest
using (
with
# get the chat
chat := <Chat>chat_id,
# get the messages to summarize
messages := (
select chat.history
filter .created_at < cutoff
),
# get the timestamp of the oldest message
# to be used as the summary's timestamp
summary_datetime := (
select messages
order by messages.created_at desc
limit 1
).created_at,
# extract the body of the messages
# to pack into the request
messages_body := array_agg((
select messages
order by .created_at
).body)
select net::http::schedule_request(
'http://127.0.0.1:8000/summarize',
method := net::http::Method.POST,
headers := [('Content-Type', 'application/json')],
body := to_bytes(
json_object_pack(
{
("chat_id", <json>chat_id),
("messages", <json>messages_body),
("cutoff", <json>cutoff),
("summary_datetime", <json>summary_datetime)
}
)
)
)
);The /summarize endpoint invokes the Summarizer agent.
Crucially, after generating the summary, the agent calls another EdgeQL function, insert_summary.
This function inserts the new summary message and marks the old messages as is_evicted.
function insert_summary(
chat_id: uuid,
cutoff: datetime,
summary: str,
summary_datetime: datetime
) -> Chat using (
with
# get the chat
chat := assert_exists((select Chat filter .id = chat_id)),
# mark the messages that are being summarized as evicted
evicted_messages := (
update chat.archive
filter .created_at < cutoff
set {
is_evicted := true
}
),
# insert the summary message
summary_message := (
insert Message {
llm_role := "system",
body := summary,
created_at := summary_datetime,
}
),
# insert the summary into the chat archive
# which automatically includes it into history as well
update chat set {
archive := distinct (.archive union summary_message)
}
);This allows us to tie summarization to data changes while keeping it off the primary path, and esures that all parts of the application have access to the most up-to-date version of history.
Generating chat titles
As a final example, new chats in our application start as "Untitled."
We can use a similar trigger mechanism to automatically generate a concise title for a chat once a few messages have been exchanged.
When a Chat is updated, if its title is still "Untitled," a trigger fires:
type Chat {
# ... other properties, links, and triggers ...
title: str {
default := "Untitled";
};
trigger get_title after update for each do (
with
# get the chat history
# again, the chat that set of the triggered is referred to as __new__
messages := (
select __new__.history
order by .created_at asc
),
# extract message bodies to pack into the request
messages_body := array_agg((
select messages.body
order by messages.created_at
))
select request_title(__new__.id, messages_body)
if __new__.title = "Untitled"
# only send the request if there isn't a non-default title yet
# otherwise do nothing
else {}
);
}This trigger schedules a request to a /get_title endpoint, which uses the Summarizer agent to create a short title and then updates the Chat object's title property in the database.
This is another non-critical task that enhances user experience without adding latency to the main interaction flow.
Conclusion
Managing long-term memory in multi-agent AI applications is a lot of work: keeping user interactions snappy, ensuring data remains consistent, and avoiding overly complex application logic for background tasks.
Gel's trigger system can help you build a clean and maintainable system. The database is the place all data eventually ends up, so it's only natural that it would dispatch events and orchestrate background processing.
-
It reduces latency: critical background tasks like information extraction, history summarization, and title generation are moved off the hot path, ensuring the user-facing
Talkeragent remains responsive. -
It simplifies architecture: there's need for external message queues or complex event dispatching systems. The logic for when to trigger background tasks is co-located with the data itself, making the system easier to understand, maintain, and evolve.
As an added bonus, we get to take advantage of Gel's features such as auth, access policies and more. Learn more about that in Gel docs or in one of the upcoming articles!


